Getting Started with Lyzr Chat Agent SDK
Lyzr’s Chat Agent is powered by a state-of-the-art chatbot architecture that super abstracts all the complexity of building an advanced LLM-powered chatbot. This enables developers to focus more on data quality, prompt quality, and the application use case instead of spending countless hours stitching together various building blocks and indexes to build the backend RAG pipeline. Lyzr’s Chat Agent integrates all the building blocks of a chatbot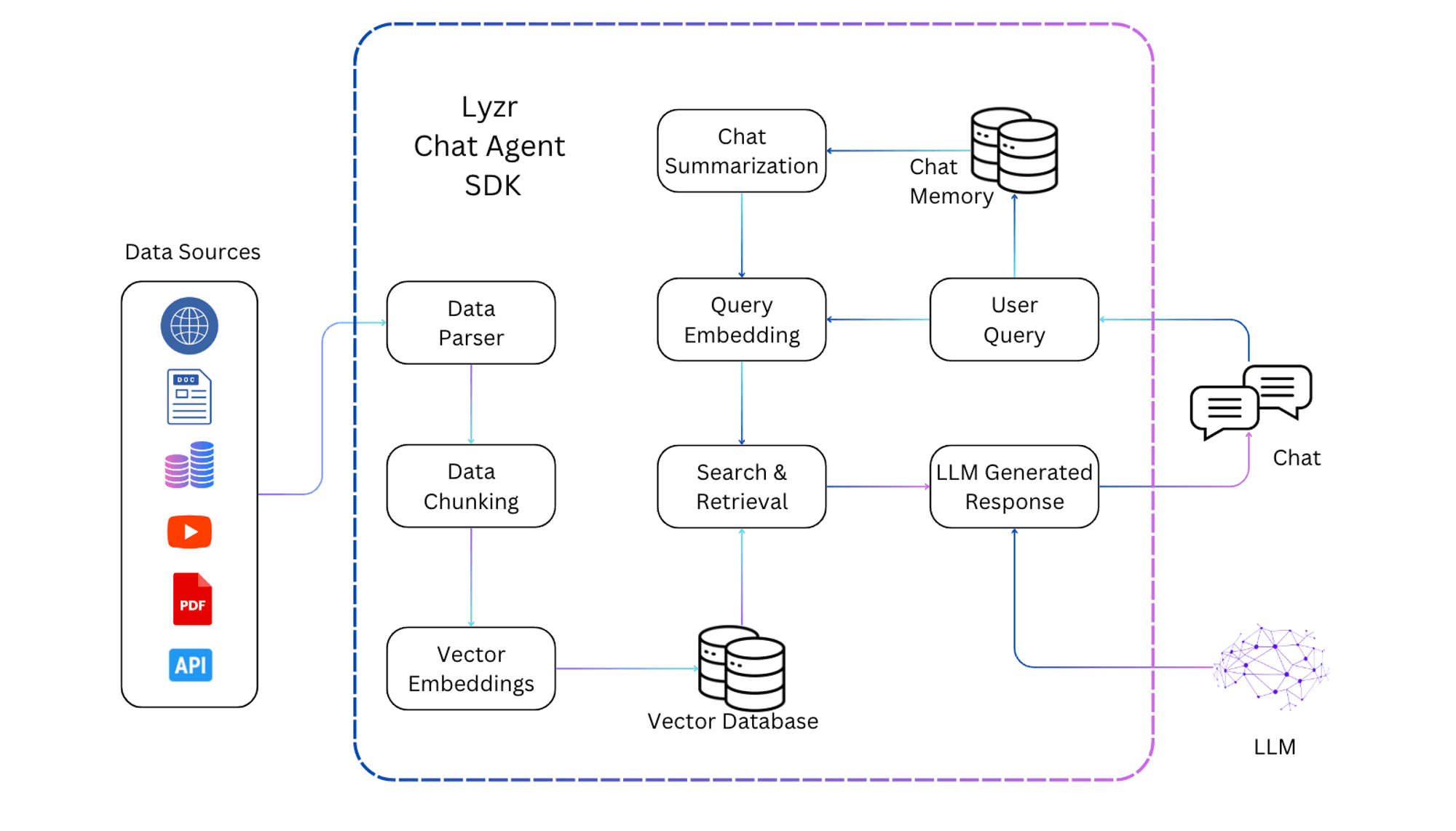
What are the various methods and arguments that you could pass to Lyzr’s ChatBot class?
Methods| Method | What it does? |
|---|---|
| pdf_chat | chat with PDF documents |
| website_chat | automatically scrape the website content and chat with website data |
| docx_chat | chat with Microsoft Word documents |
| txt_chat | chat with flat files |
| youtube_chat | chat with youtube content (must have transcriptions) |
| webpage_chat | automatically scrape the webpage content and chat with webpage data |
Chat with PDF
Sample Code 👇Use
input_dir to parse all the .pdf files from a directory.Pass a list of .pdf file paths.
Set to
true to ignore hidden files when using input_dir.Set to
true to consider the filename as the id for indexing the parsed data.Set to
true to parse files from all subdirectories.System-wide prompt to be prepended to all input prompts, used to guide system “decision making”.
A specific wrapper instruction for passed-in input queries.
The default embed model is OpenAI
text-embedding-ada-002. Default fallback model is bge from Hugging Face.Default language model is OpenAI
gpt-4-0125-preview. Default temperature is 0.The default vector store is Embedded Weaviate DB.
Default chunk_size is 1024 tokens. Default overlap is 20 tokens.
Default is none.
Default is none.
Integrations
Vector Store Integrations
Lyzr + Weaviate
Local Embedded
Local Embedded
Cloud / Self Hosted
Cloud / Self Hosted
Lyzr + Supabase Pgvector
Install vecs and supabaseLyzr + Qdrant Vector Store
Local Embedded
Local Embedded
Cloud / Self Hosted
Cloud / Self Hosted
Lyzr + LanceDB Vector Store
Local Embedded
Local Embedded
Lyzr + Azure Cognitive Search
Cloud / Self Hosted
Cloud / Self Hosted
LLM Integration
Lyzr + OpenAI
Lyzr + OpenAI
Lyzr + Azure OpenAI
Lyzr + Azure OpenAI